
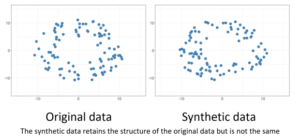
#Syntheticdata (SD) is fake data created from real data that allows secondary analysis (e.g. for research, consumer behaviour, etc) in a privacy-friendly manner (#PET). It takes an original (real) dataset and then it builds a model to characterize the distributions and relationships in that data («synthesizer», an ANN or another ML algo).
As the data generated retains the statistical properties of the original data, it can serve as a proxy for real data. It mimics real data.
Is SD #personaldata?
– It depends 🙂
– SD does not have a 1:1 relationship to real data, which reduces the chances to be considered personal data.
– However, if the model overfits the real data, it’ll replicate that data and it will be considered PD
Key legal questions to evaluate before creating SD:
– Is the use of the original dataset to generate and/or evaluate a synthetic data set regulated by law?
– Is sharing the original data set with a third-party service provider to generate the synthetic data set regulated?
– Does the law regulate the resulting synthetic data set?
EDPS – European Data Protection Supervisor will host a webinar on this topic: “Synthetic data: what use cases as a privacy enhancing technology?” (16.06.21)


0 comentarios